C++ iterators FTW!
Or one more reason to move away from raw loops.

Even though rumor has it that most of the CPU cycles are spent on sorting, I’d say that plain old for loops take the second spot. Our fingers remember this magical sequence of characters

It’s so simple and common that surely there could be nothing wrong about it, right? Well, it works, but let’s take a look at the assembly generated for checking whether we reach the end of the vector using its size

The assembly looks more complicated than most would expect

The reason for this is the way vector is implemented - it stores 3 pointers to first and last elements and the end of the data. Because of this, to compute size, we have to subtract pointer to first from the pointer to last and divide it by the size of the elements. This doesn’t look too bad, at least while the of the elements is a power of 2, which means we can use binary shift for efficient division, but it seems like there has to be a better way.
That’s where iterators come into the picture. They are one of the pillars of STL and until auto and foreach loop, used to scare C++ newcomers. So how can we implement he same check using iterators?

does the trick and generates a much more compact assembly
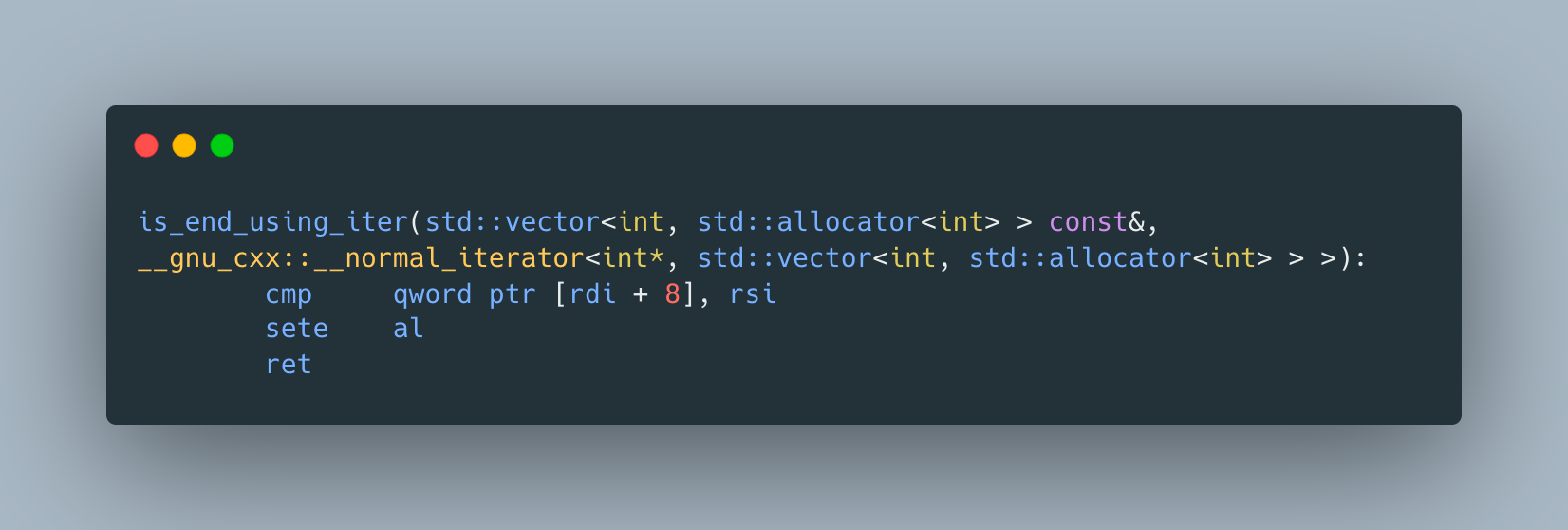
Ok, so iterators are better, but aren’t they super verbose and cumbersome to use? Even with type alias, our good old raw for loop looks more verbose

auto makes things a bit better
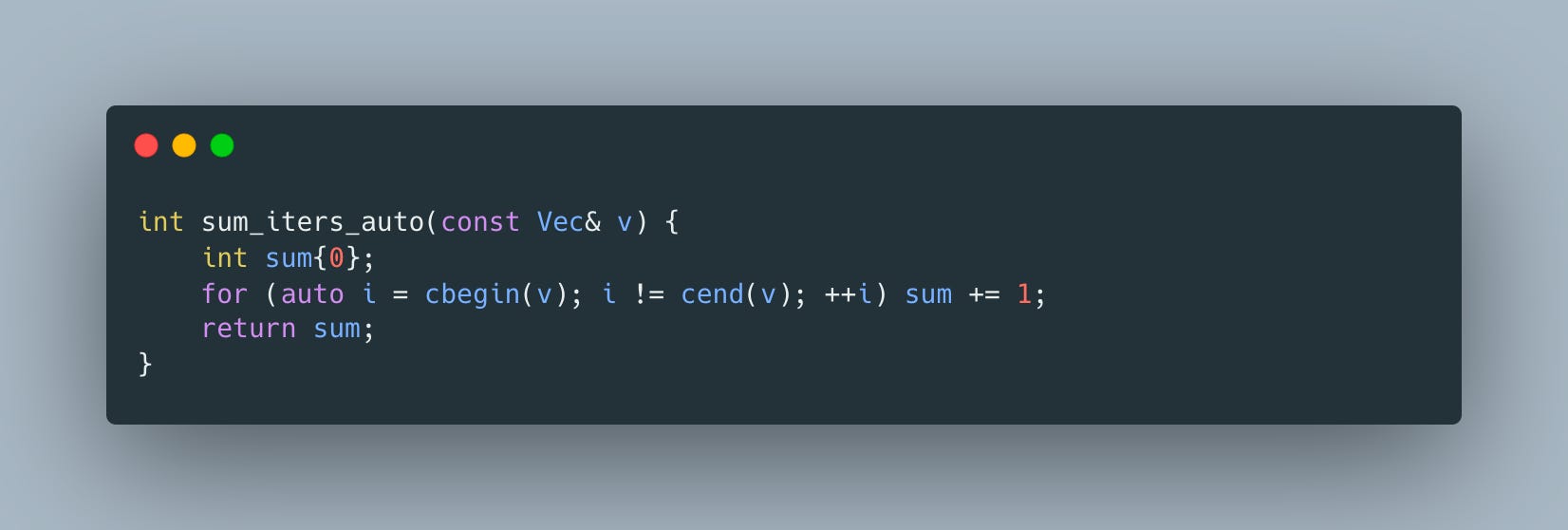
and foreach loop gets us to an even shorter version

But to take full advantage of iterators, we have to engage algorithms

or its newer version that assumes associativity and commutativity properties

These implementations are much less error-prone, performant and can easily be parallelized.
The moral of the story? Next time, before writing a raw loop, think about whether it’s possible to leverage one of the awesome STL algorithms.
Reminds me an exercise with Jason Turner. Using iterator was better than using indices. go figure :)