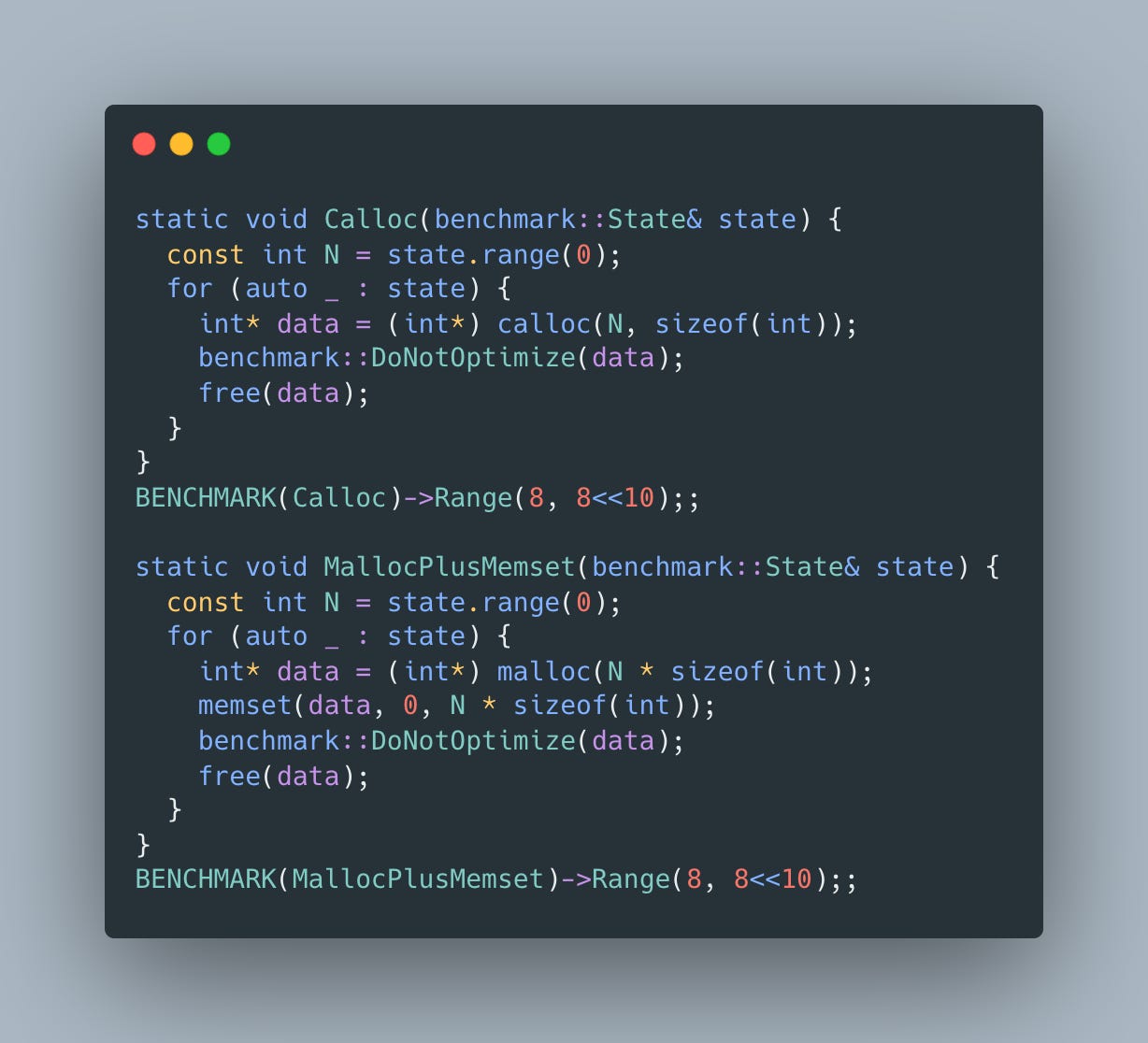
Calloc vs malloc
Or what vs how.

In addition to being concise and easier to reason about, declarative programming style oftentimes is able to deliver significant performance wins by leveraging query planners and compiler optimizers in order to turn high-level intent into the most efficient sequence of machine instructions. But this principle is not limited to programming languages and even low-level APIs can provide a way to achieve the same goal using different approaches.
To make things concrete, let’s take a look at how we can allocate a chunk of zeroed out memory chunk using calloc that returns exactly what we want:

and malloc that needs to be followed by a call to memset to make sure allocated memory does not contain any garbage but zero initialized instead

I always assumed that the runtime knowing the intent of allocating zero-initialized memory should be able to leverage the mighty OS and deliver better performance for calloc, so let’s put this assumption to the test:
The benchmarks above are parameterized to show the impact of allocation sizes. I must admit that I was surprised by the results


Turned out that calloc was ~1.5x slower for smaller allocations took about the same amount of time as malloc + memset for large allocations. It’s possible that this performance curve is not typical for normal workloads, as runtime and/or OS would have more time to prepare “clean” chunks ready for allocation, but if taken at face value the numbers stubbornly suggest usage of malloc +memset pattern which adds an additional boost in case the allocation size is small and is known statically, e.g. 8, in which case instead of function calls

compilers are able to inline memset and even use vectorized instructions

which, unfortunately, does not happen for calloc

and results in even wider 1.6X performance gap between these 2 approaches
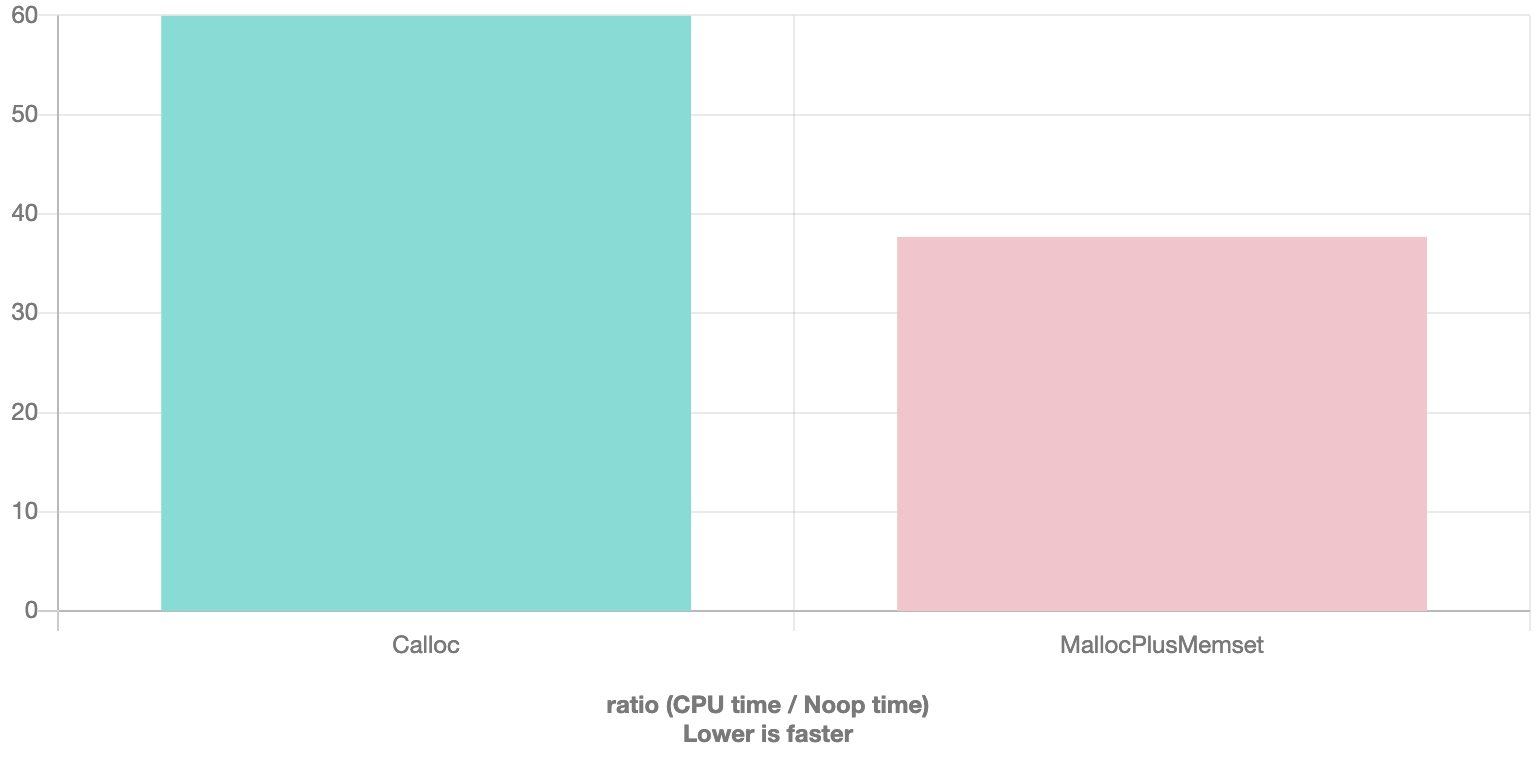
As always, this does not mean that you should never use calloc but another reminder that if performance is important, internet wisdom should only applied after measurements are done for your specific workloads.
wow! I didn't see this coming :)