Commutativity: Why Transformers Need Positional Encodings
And other consequences of order not mattering

📖 For the best reading experience with properly rendered equations, view this article on GitHub Pages.
Here’s a question that seems too simple to be interesting:
Why do Transformers need positional encodings?
The standard answer: “So the model knows where each token is in the sequence.”
But why doesn’t it know already? What is it about attention that loses position information?
The answer is a single word: commutativity.
The Property
Commutativity means order doesn’t matter:
a + b = b + a
Simple. Obvious. But the consequences run deep.
If an operation is commutative, permuting the inputs doesn’t change the output:
f(a, b, c) = f(c, a, b) = f(b, c, a)
The operation can’t tell what order things arrived in. It treats all orderings identically.
Attention Is Commutative
Look at self-attention:
Attention(Q, K, V) = softmax(QKᵀ / √d) × V
Given a sequence X = [x₁, x₂, …, xₙ], we compute:
Q = XW_Q
K = XW_K
V = XW_V
Now permute the input: X’ = [x₃, x₁, x₂, …]
What happens? The output is permuted the same way.
Attention is permutation-equivariant. Shuffle the input, get a shuffled output. The operation itself doesn’t care about order.
This means without positional encodings:
"I love you" → [embed("I"), embed("love"), embed("you")]
"you love I" → [embed("you"), embed("love"), embed("I")]These would produce the same representation (just permuted). The model literally cannot distinguish them.
Positional encodings exist because attention is commutative.
We add position information explicitly because the architecture won’t infer it.
The Design Choice
This commutativity is a feature, not a bug.
RNNs are explicitly non-commutative:
hₜ = f(hₜ₋₁, xₜ)
Each state depends on the previous state. Order is baked into the recurrence. You can’t permute the input without changing everything.
The cost: you can’t parallelize. Each step waits for the previous one.
Transformers are commutative (permutation-equivariant):
O = Attention(X)
Order is not baked in. You add it explicitly through positional encodings.
The benefit: you can parallelize. All positions are processed simultaneously.

Commutativity enables parallelization. This is why Transformers replaced RNNs for long sequences.
When You Want Commutativity
Sometimes order genuinely doesn’t matter. Then commutativity isn’t a limitation—it’s a requirement.
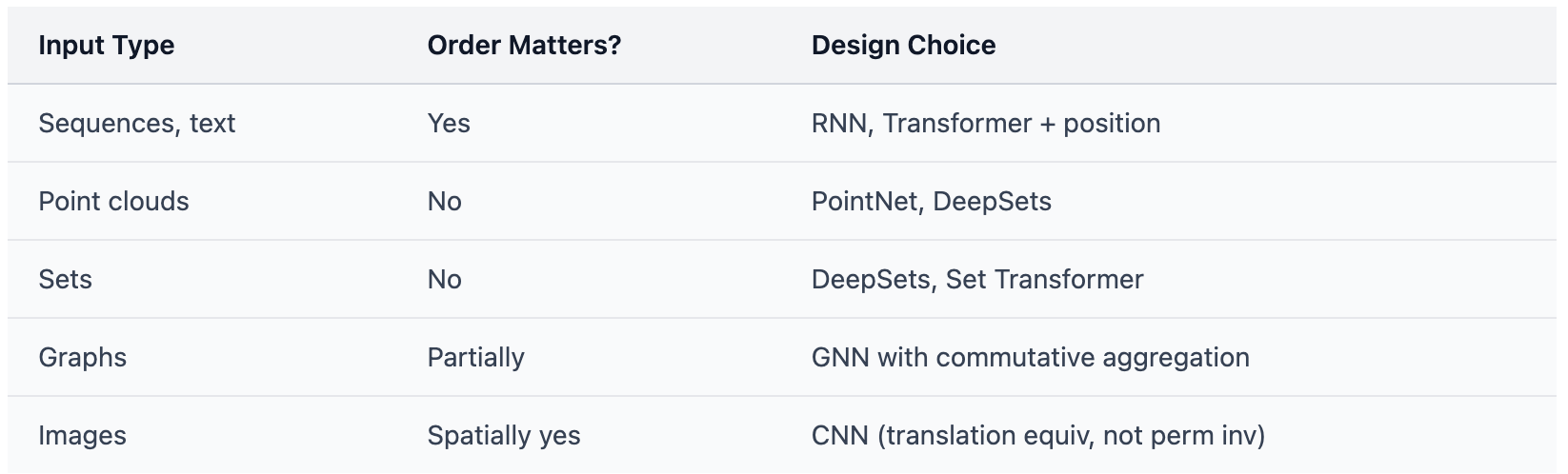
Point Clouds
A 3D scan gives you points {(x₁, y₁, z₁), (x₂, y₂, z₂), …}.
These points have no natural order. The first point scanned isn’t semantically “first.”
Your network must be permutation invariant:
f({p₁, p₂, p₃}) = f({p₃, p₁, p₂})
PointNet (2017) achieves this by design:
f(X) = g(maxᵢ h(xᵢ))
Max is commutative. Shuffle the points, get the same output.
Sets
A shopping cart. A user’s friends. Atoms in a molecule.
These are sets—order doesn’t exist.
DeepSets (2017) proved the fundamental theorem:
Any permutation-invariant function on sets can be written as: f(X) = ρ(Σ φ(x)) for all x ∈ X
Sum is commutative. The architecture is order-invariant by construction.
Graphs
In a graph neural network, you aggregate neighbor features:
hᵥ = UPDATE(hᵥ, AGG({hᵤ : u ∈ N(v)}))
The neighbors N(v) have no order. AGG must be commutative—sum, mean, or max.
When You Don’t Want Commutativity
Sometimes order is everything.
Language: “Dog bites man” ≠ “Man bites dog”
Time series: The sequence of stock prices matters
Music: Notes in order form melody; shuffled, they’re noise
Actions: The order of operations matters (usually)
For these, you need either:
Non-commutative operations (RNNs, state machines)
Explicit position encoding (Transformers)
The choice affects parallelization, inductive bias, and what the model can learn.
Gradient Aggregation: Why Training Works
Here’s a less obvious place commutativity matters.
When you train on a minibatch, you compute:
L = (1/N) Σ L(xᵢ, yᵢ)
∇L = (1/N) Σ ∇L(xᵢ, yᵢ)
The sum of gradients is commutative. This enables:
Minibatch training: Compute gradients for samples in any order, sum them.
Gradient accumulation: Split a large batch across multiple forward passes, sum the gradients.
Distributed training: Compute gradients on different machines, sum them (all-reduce).
If gradient aggregation weren’t commutative, distributed training would be impossible. The order of machines would matter.
Pooling: The Invariance/Information Trade-off
Global pooling—mean, max, sum—is commutative.
This gives you translation invariance:
[ cat in left of image ] → pool → representation
[ cat in right of image ] → pool → same representationThe pooled representation doesn’t know where the cat was.
The trade-off: commutativity destroys positional information.
Want invariance? Use commutative pooling.
Want to preserve position? Don’t pool, or use position-aware alternatives.
This is why object detection uses feature pyramids instead of global pooling—you need to know where things are.
Designing with Commutativity
When building an architecture, ask:
Does order matter in my input?
Does order matter in my output?
If you’re generating sequences, you need autoregressive structure—fundamentally non-commutative.
Can I parallelize?
Commutative operations can be parallelized and distributed. Non-commutative ones often can’t.
The Floating-Point Footnote
One subtlety worth knowing:
In exact arithmetic, addition is both commutative (a + b = b + a) and associative ((a + b) + c = a + (b + c)).
In floating-point:
Commutativity: preserved ✓
Associativity: broken ✗
>>> (1e20 + (-1e20)) + 1
1.0
>>> 1e20 + ((-1e20) + 1)
0.0
Reordering is safe. Regrouping isn’t.
This means parallel reductions (which require regrouping) can give slightly different results on different runs.
This contributes to ML non-reproducibility, but research from Thinking Machines shows the primary culprit is subtler: GPU kernels change their reduction strategies based on batch size. When server load varies, batch sizes vary, kernel behavior varies—and you get different results even with identical inputs.
Either way, this is a numerical concern, not an architectural one. The mathematical design choice—commutative or not—remains valid.
The Takeaway
Commutativity is about order invariance.
Where order doesn’t matter—sets, point clouds, graphs—use commutative operations. You get parallelization and natural invariance.
Where order matters—sequences, time series—either use non-commutative operations (RNNs) or add position explicitly (Transformers).
Transformers need positional encodings because attention is commutative. The architecture processes all positions symmetrically. Order must be injected from outside.
This single property—commutativity—explains:
Why Transformers parallelize and RNNs don’t
Why PointNet works on point clouds
Why GNNs use sum/mean/max aggregation
Why global pooling loses spatial information
Why distributed training is possible
The algebra isn’t abstract. It’s in every architecture you use.
See also: The One Property That Makes FlashAttention Possible — Associativity is the license to parallelize, chunk, and stream.
Further Reading
Zaheer et al., “Deep Sets” (2017) — The foundational theorem on permutation-invariant functions
Qi et al., “PointNet” (2017) — Processing point clouds with max pooling
Vaswani et al., “Attention Is All You Need” (2017) — Transformers and positional encodings
Bronstein et al., “Geometric Deep Learning” (2021) — Symmetry and invariance in neural networks
Thinking Machines, “Defeating Nondeterminism in LLM Inference” (2025) — Why batch-invariance failure causes non-reproducibility