Fixing famous binary search bug efficiently.
Or fewer instructions FTW!

Jon Bentley was a renowned computer scientist and author of the book “Programming Pearls”. In one of the chapters of the book, he described an algorithm for binary search, a well-known search algorithm that finds the position of a given value in a sorted array.
Bentley's implementation of binary search was correct for most cases, but it contained a subtle bug that could cause it to fail for large arrays. The bug was in the line of code that calculated the midpoint of the array. Bentley's code used the following expression to calculate the midpoint:
int mid = (low + high) / 2; This expression works correctly for most cases, but it can overflow for large values of the variables low and high. In fact, helpful compilers can point out such bugs in obvious cases like the one below
warning: overflow in expression; result is -4 with type 'int' [-Winteger-overflow]
return (std::numeric_limits<int>::max() - 2 + std::numeric_limits<int>::max()) / 2;This means that if low is std::numeric_limits<int>::max() - 2 and high is std::numeric_limits<int>::max(), then the expression (low + high) / 2 will overflow and produce the value -4 and result in undefined behavior.
The bug in Bentley's binary search implementation went undetected for over 20 years and its fix usually looks something like
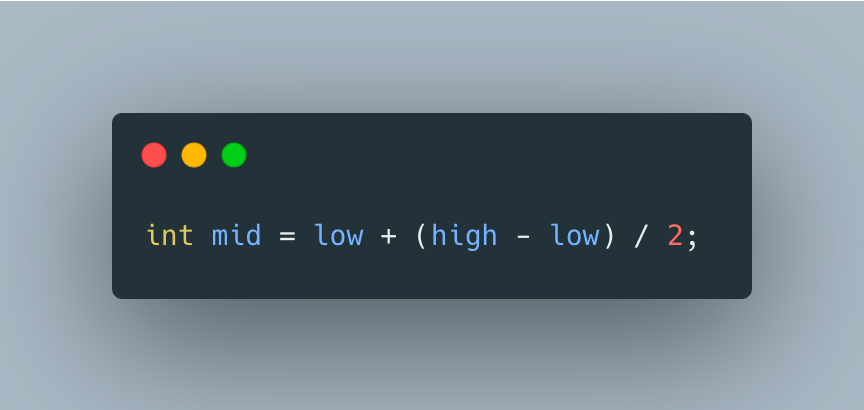
It makes sense since we’d like to add half of the distance between low and high to get to their midpoint. Is this the best we can do though? I didn’t bother to find out until a few days ago when I accidentally noticed

go Go’s implementation of sort.Search. Even if adding two huge signed integers results in overflow, by casting their sum to unsigned int, we can use the sign bit to store an overflow. After shifting the number by 1 bit to the right the sign bit is no longer set and we can cast it back to signed version.
To see what difference it makes, let’s take a look below implementations of midpoint
| int midpointb(int l, int r) { | |
| return (l + r) >> 1; | |
| } | |
| int midpointw(int l, int r) { | |
| return l + (r - l) / 2; | |
| } | |
| int midpoint(int l, int r) { | |
| return static_cast<unsigned int>(l) + static_cast<unsigned int>(r) >> 1; | |
| } |
where midpointb is the common buggy version, midpointw - common working version and midpoint - the optimized alternative. midpointw clearly uses more instructions and as such is likely to be more expensive.

What’s interesting though is how similar midpointb and midpoint assemblies are. In fact, it’s just a 1 letter difference sar vs shr. It’s a very important difference though - SAR preserves the most significant bit, unlike SHR, so even when we shift the overflow bit to the right, it’s still going to affect the sign bit in the resulting signed integer and cause the wrong result.
Go’s assembly is a little different but the idea is the same

And here’s the same in Zig

and its assembly

Does it matter in practice though? Let’s see
| #include <numeric> | |
| int midpointb(int l, int r) { | |
| return (l + r) >> 1; | |
| } | |
| int midpointw(int l, int r) { | |
| return l + (r - l) / 2; | |
| } | |
| int midpoint(int l, int r) { | |
| return static_cast<unsigned int>(l + r) >> 1; | |
| } | |
| int L = std::numeric_limits<int>::max(); | |
| int R = L - 2; | |
| static void MidpointW(benchmark::State& state) { | |
| for (auto _ : state) { | |
| benchmark::DoNotOptimize(midpointw(L, R)); | |
| } | |
| } | |
| BENCHMARK(MidpointW); | |
| static void Midpoint(benchmark::State& state) { | |
| for (auto _ : state) { | |
| benchmark::DoNotOptimize(midpoint(L, R)); | |
| } | |
| } | |
| BENCHMARK(Midpoint); | |
| static void StdMidpoint(benchmark::State& state) { | |
| for (auto _ : state) { | |
| benchmark::DoNotOptimize(std::midpoint(L, R)); | |
| } | |
| } | |
| BENCHMARK(StdMidpoint); |
As expected our version is much faster than the recommended one

and and its also a lot faster than std::midpoint from the standard library.
Don’t forget to make sure that both variables indeed stay within positive range (0, max«unsigned int»), so “left” should be initialized as 0 and not -1, as some binary search implementations do.
You can play more with different implementations using links below:
Go’s compiler explorer - https://compiler-explorer.com/z/sz51jGM8s
Zig’s compiler explorer - https://godbolt.org/z/E5vez4sEv
C++ bench - https://quick-bench.com/q/hIof5am90-S3qBdZRBiZCs6of7Q
Isn't your implementation UB? You cast after the addition? So you're casting the result, after the signed overflow (UB) would have already happened, no?