Optimize for the common case
Or how often do you really use non-ascii identifiers?

While browsing Go’s compiler codebase I’ve noticed a comment that I often leave myself:
Optimize for the common case of an ASCII identifier.
The motivation behind it is also included:
Ranging over s.src[s.rdOffset:] lets us avoid some bounds checks, and avoids conversions to runes. In case we encounter a non-ASCII character, fall back on the slower path of calling into s.next().
It makes perfect sense, especially since I’ve never actually seen non-ASCII characters being used in identifiers. Authors of Go emphasize their focus on simplicity, so each optimization is carefully evaluated and added only if it’s absolutely critical to maintain supersonic compile time, which is one of the distinguished features of Go. So is it that big of a deal? To find out, we’ll use a very simplified, and technically broken since it assumes all characters are ASCII, version for processing source bytes

and a simplified version that decodes bytes into runes, although not as efficiently and skillfully as it’s done in Go compiler,

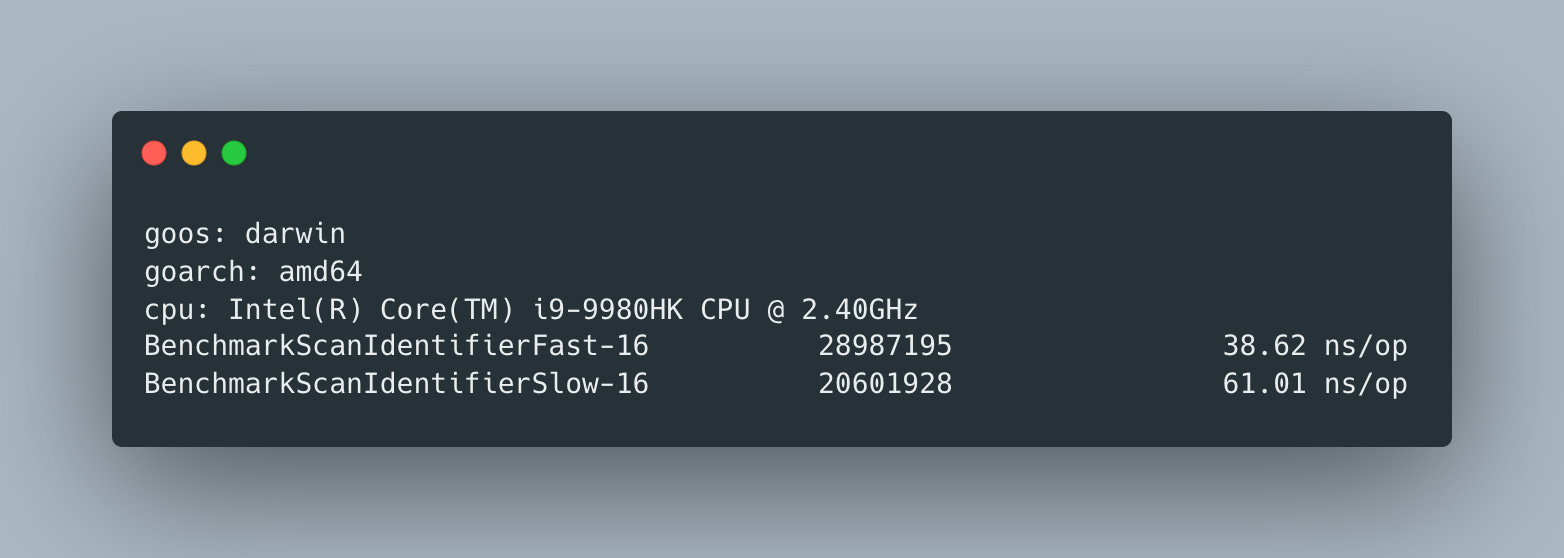
To measure their performance we’ll use following trivial benchmarks

And, unsurprisingly, slow version is almost 2X slower
Following function implementations are too simplistic to be fully representative of real-world impact of not having logic optimized for the common case, but when working on a performance critical section of code, think about whether common case requires full complexity of a general solution and if not, if performance difference justifies additional complexity for handling it separately.