Polymorphic vectors.
Or std::variant is not the only alternative to inheritance.

Inheritance is a powerful feature in C++, but it can also have a negative impact on performance. Common performance issues that can occur when using inheritance in C++:
Indirection: When a member function of a base class is called from a derived class object, an additional level of indirection is required. This can lead to a performance penalty, especially if the member function is called frequently.
Virtual function dispatch: When a virtual function is called from a derived class object, the compiler must first determine which overridden function to call. This can lead to a performance penalty, especially if the virtual function table is large or if the virtual function is called frequently.
Because of this performance sensitive applications use Data-oriented design (DOD) instead of OOP. It is a software development paradigm that emphasizes the organization of data over the organization of code. This can lead to improved performance by making it easier for the compiler to optimize code and by reducing the number of cache misses.
Here are some of the ways that DOD can help with performance:
Efficient data layout: DOD encourages the use of efficient data layouts, such as contiguous memory allocation and alignment. This can help to improve cache performance by making it easier for the CPU to access data.
Reduced indirection: DOD discourages the use of indirection, such as pointers and virtual functions. This can help to improve performance by reducing the number of times the CPU has to access memory.
Simpler code: DOD encourages the use of simpler code, such as functions that are short and easy to understand. This can help to improve performance by making it easier for the compiler to optimize code.
DOD is not a silver bullet, but it can be a valuable tool for improving performance. By following the principles of DOD, developers can write code that is more efficient and easier to optimize.
Here are some specific examples of how DOD can be used to improve performance:
Use contiguous memory allocation: Contiguous memory allocation can help to improve cache performance by making it easier for the CPU to access data. For example, if a struct is allocated contiguously in memory, the CPU can access all of the members of the struct without having to jump around in memory.
Use alignment: Alignment can help to improve cache performance by ensuring that data is stored in memory in a way that is efficient for the CPU to access. For example, if a struct is aligned to a 4-byte boundary, the CPU can access all of the members of the struct using a single 4-byte load instruction.
Avoid indirection: Indirection can slow down code by making it more difficult for the compiler to optimize code. For example, if a function is called using a pointer, the compiler cannot inline the function, which can lead to performance loss.
Write simple code: Simple code is easier for the compiler to optimize, which can lead to performance gains. For example, a function that is short and easy to understand is more likely to be inlined by the compiler than a function that is long and complex.
By following the principles of DOD, developers can write code that is more efficient and easier to optimize. This can lead to improved performance in applications.
As an illustration of the problem, I often see authors use a hierarchy of shapes.

Leaving aside the arguments about whether such hierarchy makes any sense, let’s see how it can be used

It’s pretty clear that this code results in usage of heap, indirection and other issues we’ve noted above. So what are our options? These days, std::variant is usually recommended as an alternative:

This looks like a clear improvement - we no longer have to deal with inheritance, indirection, allocations etc. Let’s use the following benchmark to confirm our expectation
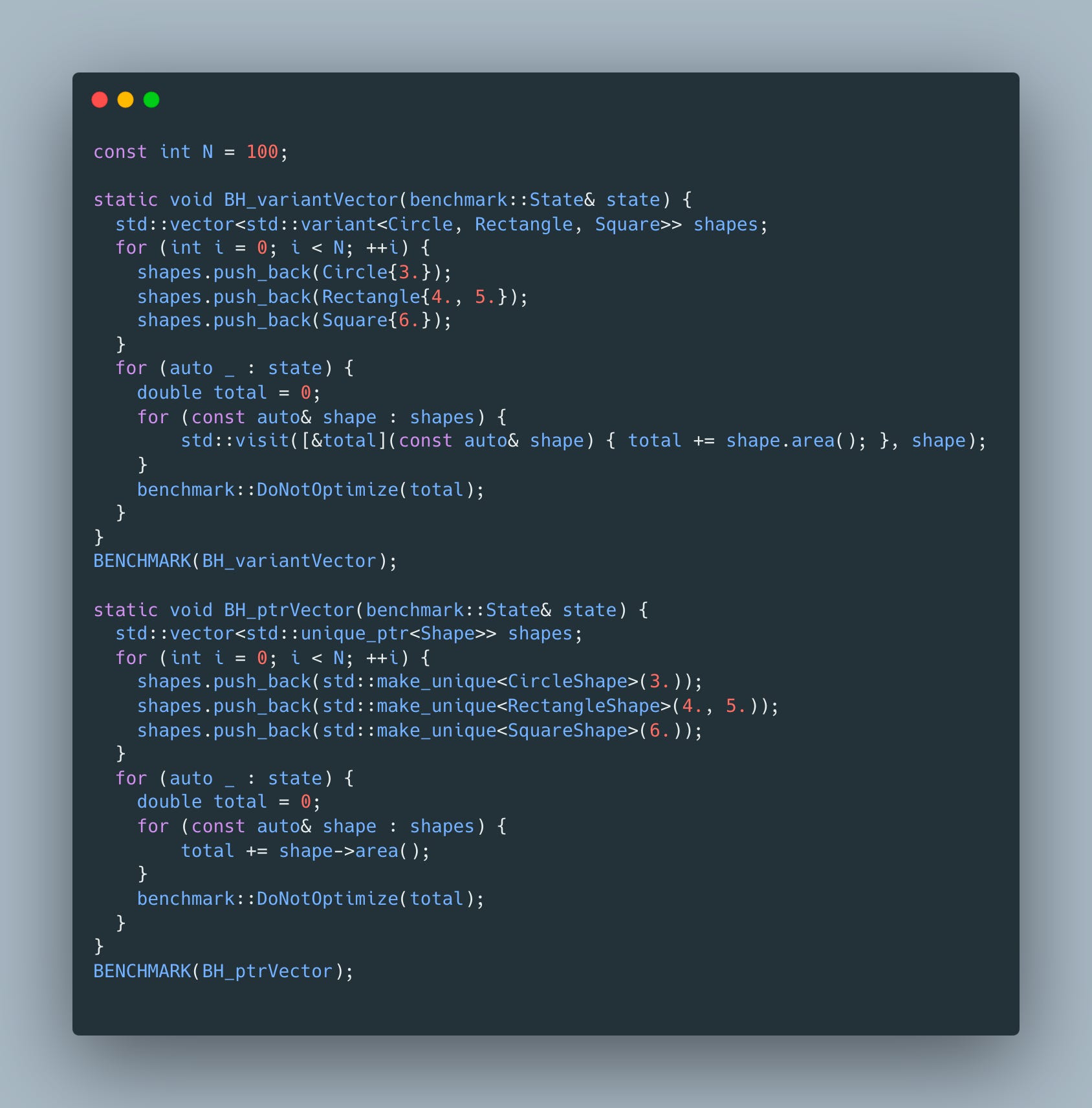
As expected, the variant version is faster

2.7X faster in fact. We could stop here, but I always wondered why do we need a variant at all? What if instead of using a sum type at the level of the shape, we switch from array of structs to struct of arrays approach? Let’s try
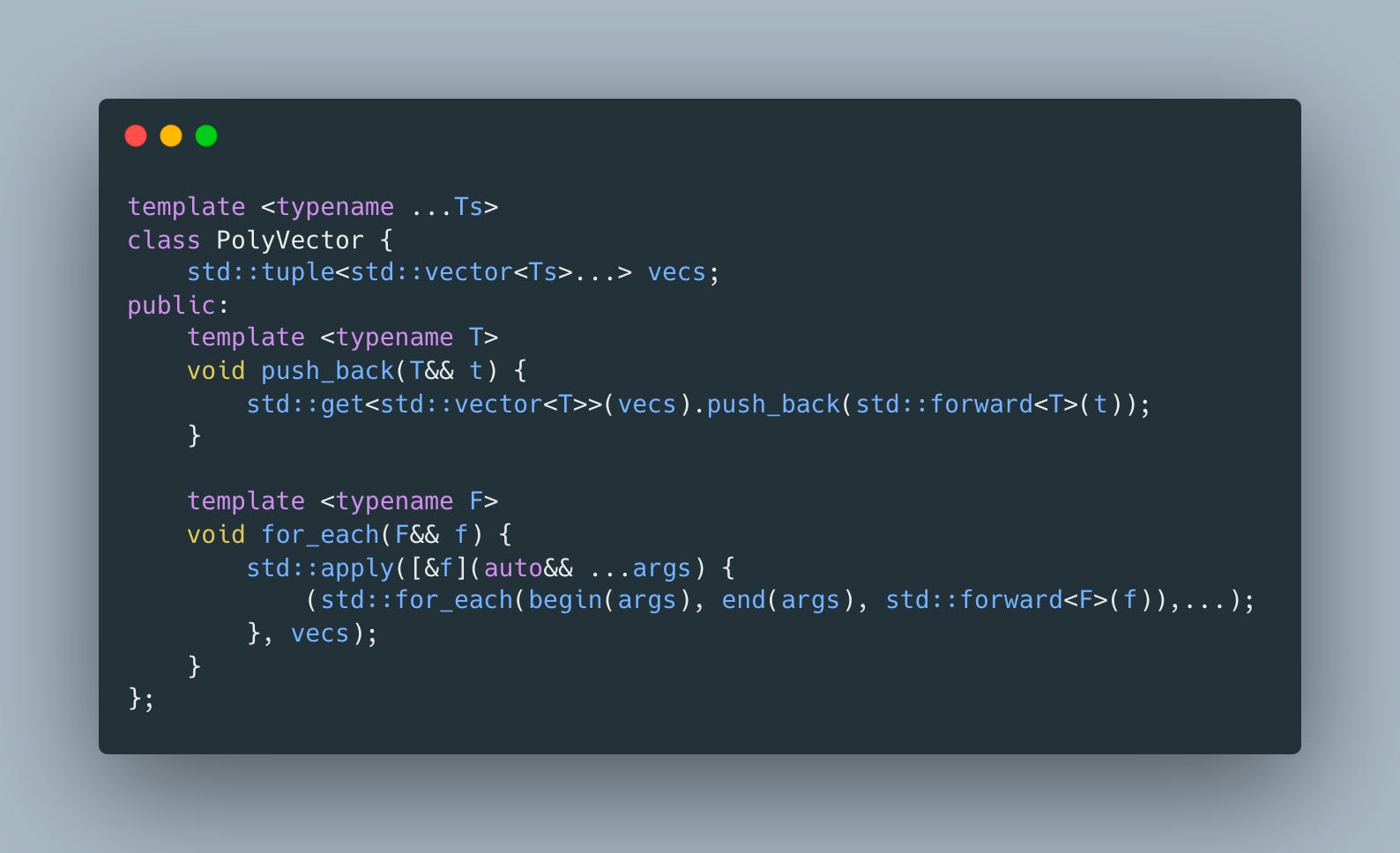
This implementation makes it possible to use plain old structs with 0 memory overhead unlike variant version which has to make variant large enough to fit the largest shape.
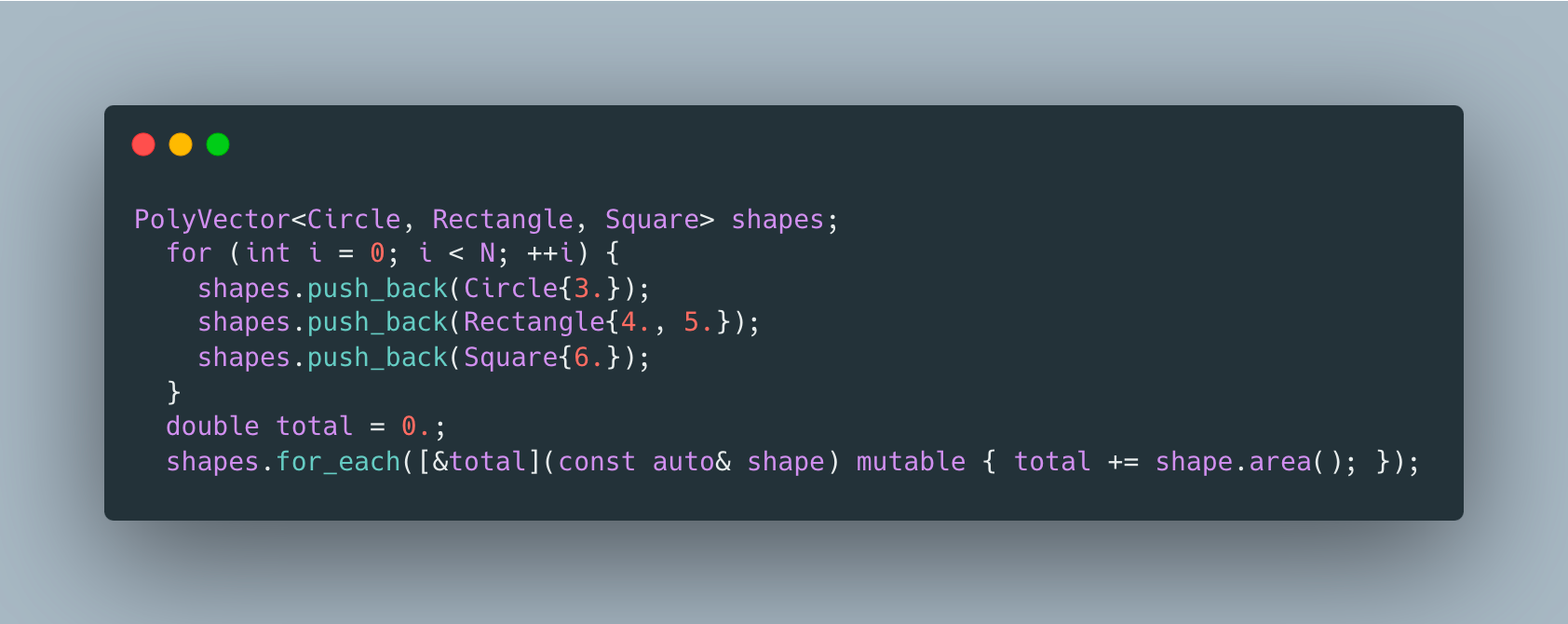
I like this version, but what about its performance? We’ll use the following benchmark:

And looks like it’s 10% faster than the variant version

Obviously these numbers can be different depending on the sizes and distribution of shapes used, so don’t forget to benchmark performance for your specific use-case.
nice!
btw, I dont think you need the ctor of PolyVector, do you?
(if we do need it, we should = default it, but I dont think we need it unless I'm missing something).
I tend to be confused w/ invoke vs apply. this is a good ref: https://stackoverflow.com/questions/52449163/what-is-the-difference-between-stdinvoke-and-stdapply
since you are using tuple, apply is the right approach as you have it above.
thanks!