
Random vs sequential memory access.
Random vs sequential memory access.
Or why memory is just a faster magnetic tape.

In my “Old pattern powering modern tech” article I’m claiming that memory is just a faster magnetic tape, which sounds strange given how different seeks are for magnetic tape, which does not support random access, and RAM (random-access memory), which has random in its name.
For everyone who had experience using a tape recorder it’s fairly obvious why random access is expensive - especially, if you, like me have used pencil for rewinding.

But it’s not immediately obvious, why would RAM random and sequential access latency would be so different. Some of the reasons include:
RAM reads are performed in chunks, usually 4KB or 8KB, which means that when accessing data sequentially, we get neighboring data for free

Row buffers act as a cache within DRAM
Row buffer hit: ~20 ns access time (must only move data from row buffer to pins)
Empty row buffer access: ~40 ns (must first read arrays, then move data from row buffer to pins)
Row buffer conflict: ~60 ns (must first writeback the existing row, then read new row, then move data to pins)
Cache prefetching - technique CPUs are using to anticipate data that will be needed soon and fetch it into their caches, that are much faster.



This all sounds reasonable, but it’s just a theory, so it’s time to put this theory to the test. For benchmarking we’ll use a simple summation function that in addition to input numbers also accepts the slice that determines access ordering
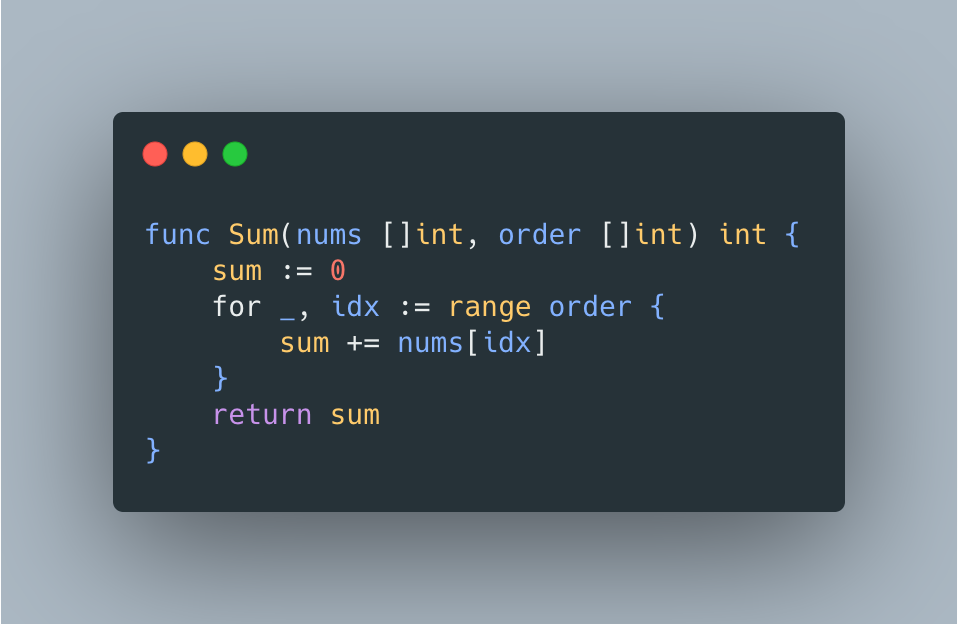
Now we’ll use 2 benchmarks to measure time it takes to sum all the elements sequentially

and in random order

Visually these access patterns can be represented as
")
The numbers obviously depend on the number of elements in the input slice which is controlled by the COUNT constant.
When it’s small, like 8, there is no performance difference
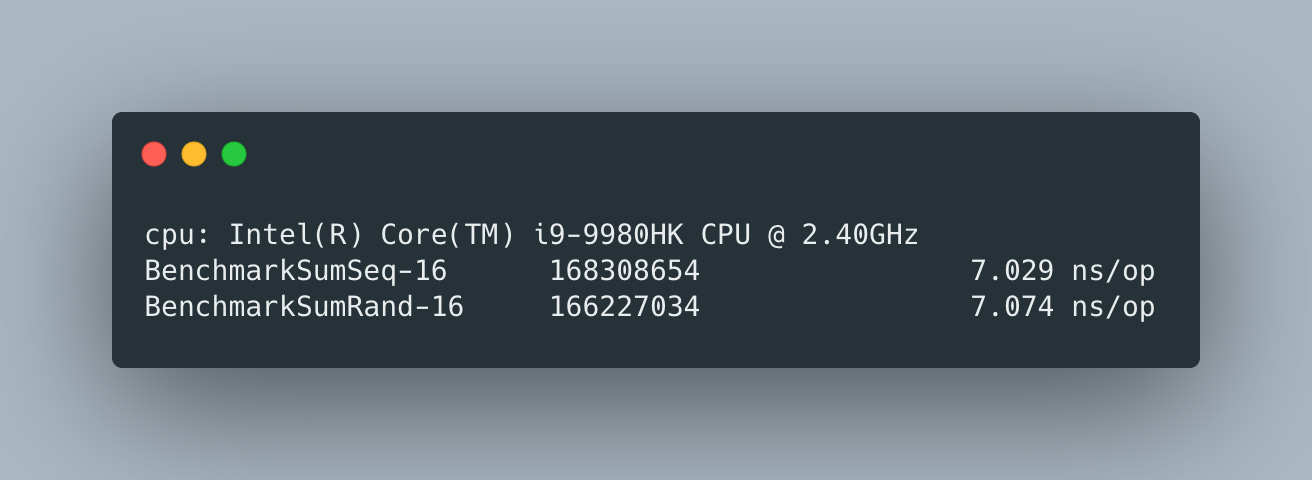
which is expected, since the entire slice fits into the cache row.
Even when COUNT is 1024, the difference is still insignificant

which is likely explained by the size of RAM page we read in one go.
At 1048576, we still don’t see an expected speedup

But as soon as we reach 16777216 performance gap becomes significant - almost 35X

And this trend continues as the number of elements grows.
Similar hardware memory hierarchy is typical for many device controllers, including SSDs, so accessing data in a sequential way brings similar performance gains and often is a cheap and easy way to boost performance.