

Recursive vs iterative.
Or turning implicit into explicit.

Recursion is an extremely powerful and natural way of solving problems in terms of their simpler versions. Its declarative nature allows us to focus more on “what” instead of “how” and as such easier to understand and reason about. Famous interesting problems that are much easier to solve using recursion include a Sierpinski gasket

and Towers of Hanoi

as well as numerous algorithms like merge sort

The “magic” behind recursion is a stack which maintains execution context, so that we know how to proceed once we get a subproblem result

In fact, stack is so useful that CPUs even have dedicated instructions for performing common operations
![Runtime Stack Managed by the CPU, using two registers SS (stack segment) ESP (stack pointer) - [PPT Powerpoint]](https://substackcdn.com/image/fetch/$s_!sFs_!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fbucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com%2Fpublic%2Fimages%2F1e945261-d277-4a0c-853c-5b11a6e38abd_680x510.png "Runtime Stack Managed by the CPU, using two registers SS (stack segment) ESP (stack pointer) - [PPT Powerpoint]")
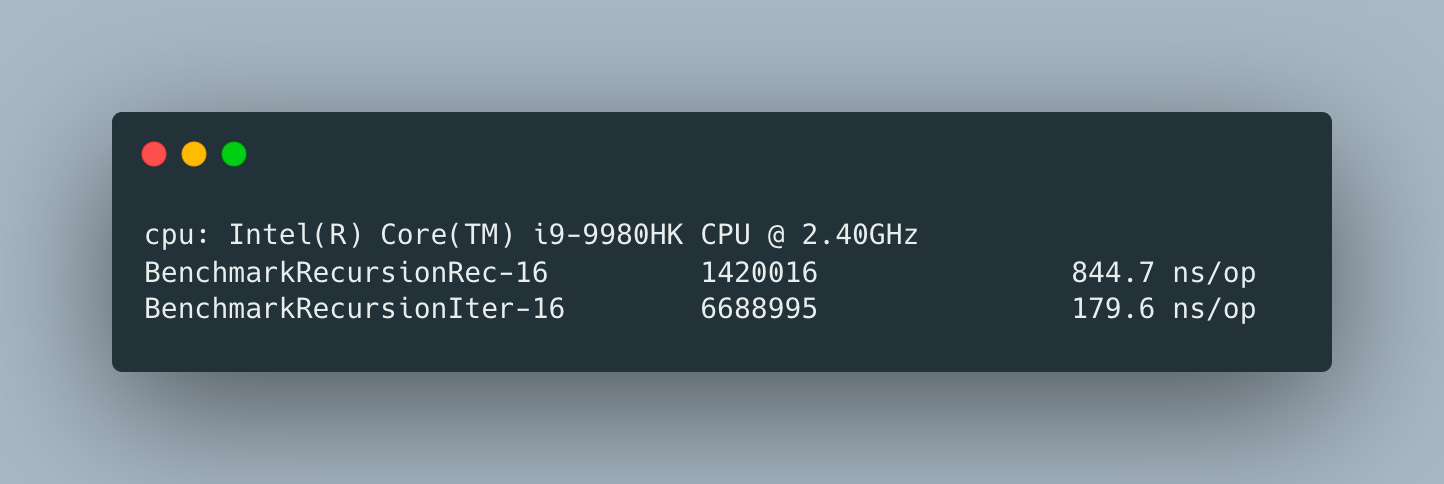
Because of hardware support and a long history, we should expect recursion to be performant. So today, we are going to take a look at some trivial uses of recursion and how its performance compared to an iterative version.
Let’s start with a trivial single argument function

and benchmark their execution time using

And the results below show that the iterative version is almost 5 times faster than its recursive cousin.
Since our functions have just a single integer parameter, the only allocations used by exploreIter are those responsible for extending stack slice. What if we have 2 parameters wrapped into a struct? Let’s see

Technically we could avoid usage of params struct by using parallel arrays pattern but even with extra struct allocations

still suggest that iterative version is faster

These are arguably too abstract and not very useful functions, but being so simple they make it much easier to focus on recursive vs iterative aspect and in future posts we’ll take a look at more practical examples.