Space-time tradeoff?
Or using less memory to reduce time.

When it comes to performance, it’s uncommon to encounter a famous space-time tradeoff - a way of solving a problem or calculation in less time by using more storage space, or by solving a problem in very little space by spending a long time. Caches and dynamic programming are common examples of this tradeoff - storing already computed subproblem results makes it possible to avoid repeated expensive computations and to same time.
This makes sense, but only if used memory is put to a good use, since, after all, since working with memory is orders of magnitude slower than crunching data loaded into the registers. Because of this, we should strive to use the least amount of memory necessary to store only results that are still going to be reused.
Let’s use famous Levenshtein distance as an example. Its most common implementations uses NxM matrix

It’s easy to notice that we only access previous rows of the matrix, so it doesn’t make much sense to use an entire matrix - we can easily get by with just 2 rows
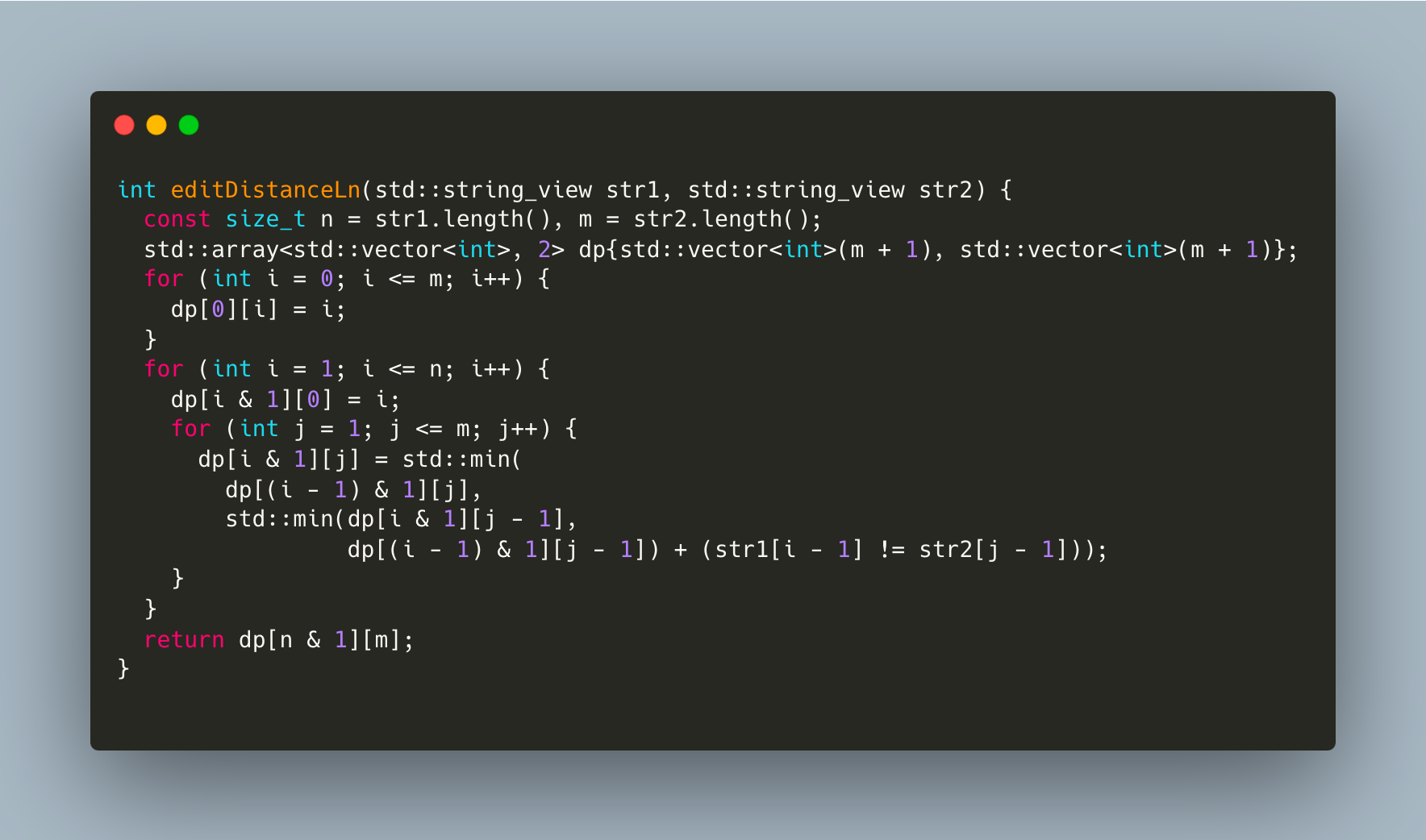
In fact, it’d be even better to pick the smaller size of the string to be the size of the row, but I’ll leave this as an exercise to curious readers.
Obviously, this way, we can save some memory, but how does it affect performance?

Turns out we get almost 3X speedup

Not bad at all given how little effort it took to get an optimized version.
Btw, this can be one more reason to be careful when using things like “functools.cache” in Python for memoized implementations, since on top of using hashtables, that are significantly more expensive than matrices, they also store all values, unless something like lru_cache is used with size limit.