Specialized data structures.
Or power of simplicity.

Being abstract is something profoundly different from being vague … The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.
Unfortunately it’s not uncommon to see improper usage of abstraction that results in bloated, poorly performing and hard to maintain software. The area where it shines though is data structures in general and abstract data types in particular. It allows us to pick the best implementation for specific use-cases, inputs and complexity requirements. At the same time, we often don’t take the full advantage of its power by limiting choices to generic implementations instead of embracing highly specialized implementations. Let’s take a very common and useful data structure - set, which is an unordered collection of elements. To keep the article focused, we’ll use an extremely limited immutable set interface

Languages like Java provide tree and hash based implementations of a set, but we’ll use only the most common, hash based, as a baseline

Now, let’s write simple specialized implementations for singleton collection

and a “small” set that we’ll use to store 2 items
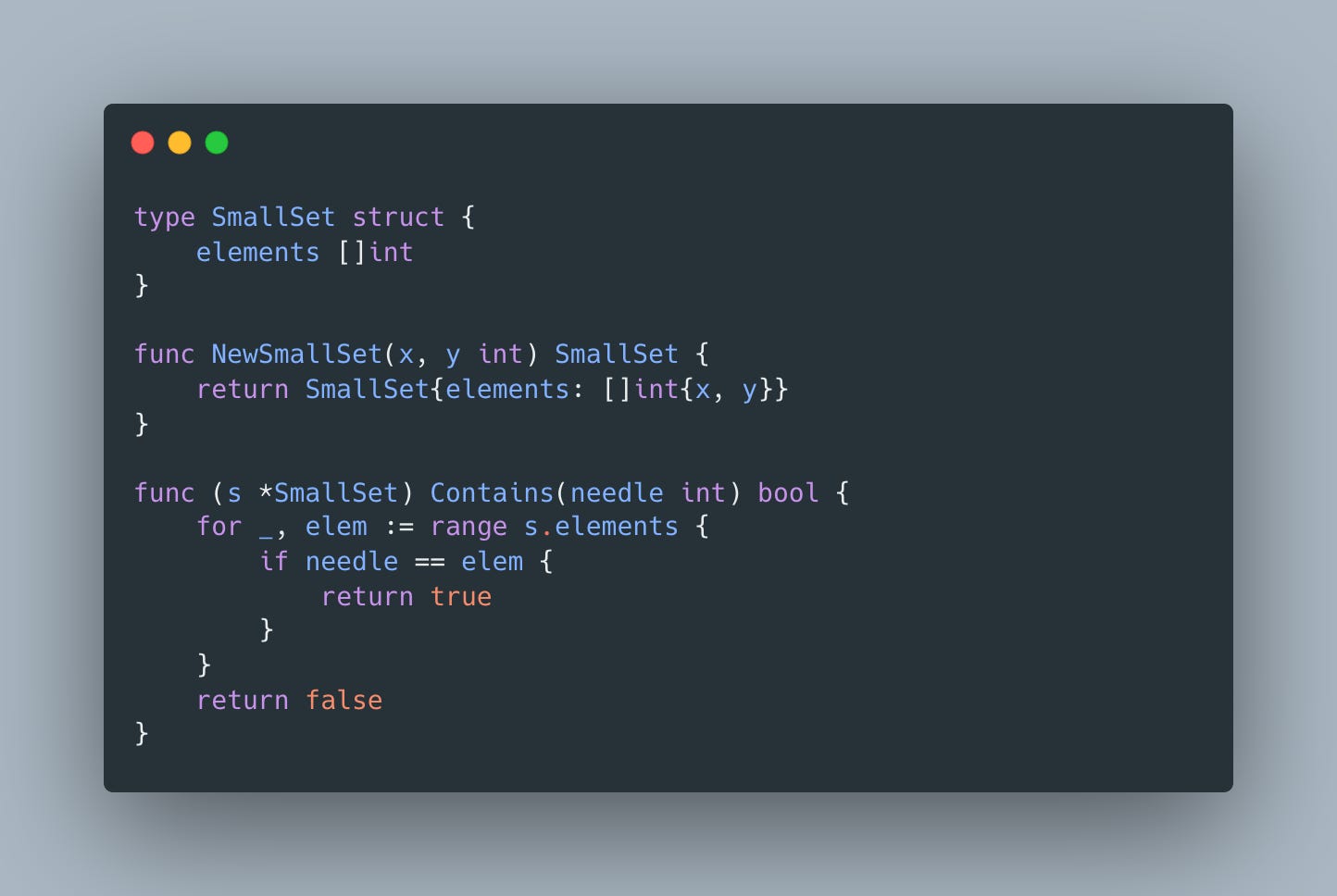
In order to compare the implementations we’ll use the following benchmarks

And the results are

and show that specialized singleton contains implementation is almost 8X faster than a generic hash set implementation and small set backed by 2 arrays is ~40% faster for 2 element collections.
Even though writing such specialized data structures may seem like a lot of additional work, it’s only the case when interfaces they implement are very wide, which is a design smell, or they are not simple, which is likely negatively impact its performance. When used properly, writing such implementations is a lot of fun and deliver unmatched performance and memory usage showcasing the power of simplicity.
Life is really simple, but we insist on making it complicated.
― Confucius