Surprisingly expensive Python.
Or things that shock devs coming to Python from compiled languages.

Being fortunate to mostly use programming languages with advanced optimizing compilers, it’s very easy to forget that
Any performance problem in computer science can be solved by removing a layer of abstraction.
- Dave Clark
C++ and Rust developers don’t have to worry about the cost of accessing struct members or calling a small function, since former are just address offsets and latter are usually inlined or have relatively low call overhead. Because of this, they often operate under assumption that the cost of abstractions in other languages are somewhat similar. Well, let’s see if that’s the case for extremely common abstractions in Python.
First, let’s introduce a value holder that we’ll use for benchmarking
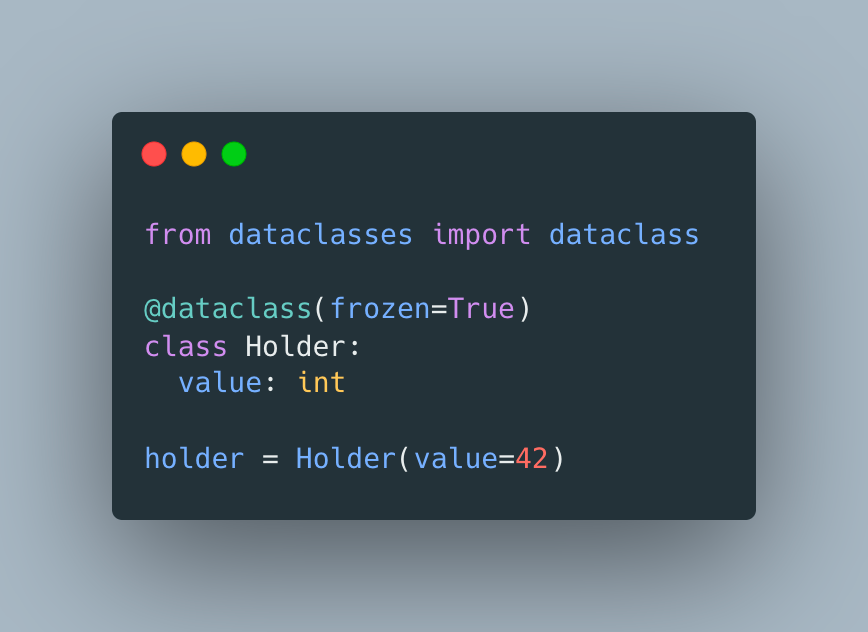
now, let’s compare 2 snippets below

and

Surely there is no difference, right? Let’s take a look at the numbers:
105 ns ± 0.575 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)vs
95.8 ns ± 11.3 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)Not the end of the world, but it’s somewhat surprising that such a trivial operation already adds almost 10% overhead. But don’t forget - every attribute access is really a dictionary lookup, so things can get even worse if there are more attributes.
But can’t we remove the dictionary lookup overhead by switching to __slots__? Let’s give it a try:

and use the same “inefficient” usage pattern as above

Oh no!
117 ns ± 1.62 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)It’s even worse! I’ll leave this as an exercise for you, my dear reader, to figure out why that’s the case and you can use codelab playground as a starting point.
Now, let’s also take a look at another super common use-case:

We’ve already established that it’s not the most efficient way of creating a list, but this time instead of using more idiomatic Python, we’ll apply the same manual “caching” and see if it makes a difference
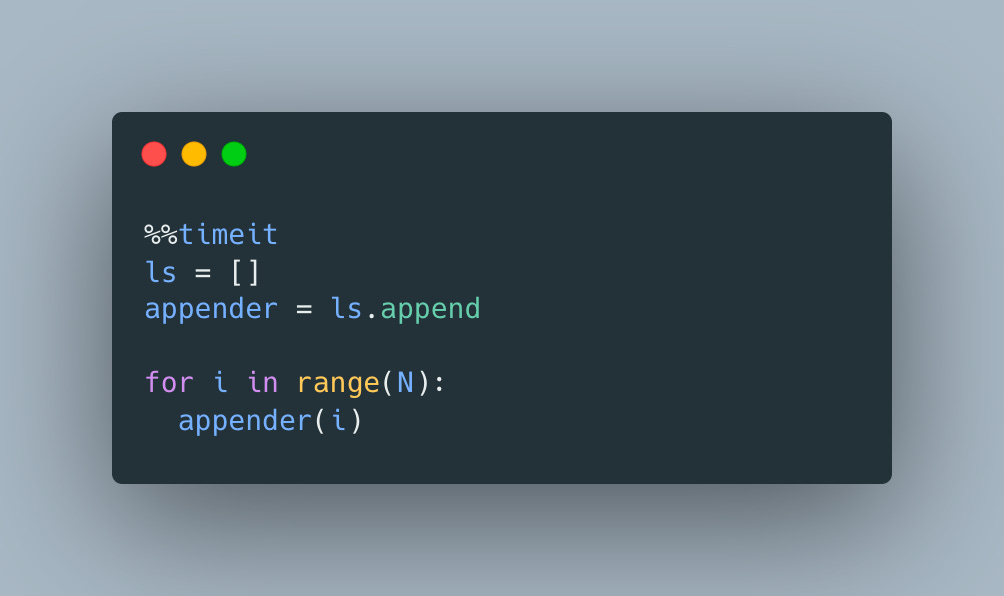
Since we use list append method in both versions, the time difference should mostly reflect the attribute lookup overhead. So what is it?
802 µs ± 8.49 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)vs
653 µs ± 33.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)Ouch, almost 20% of overhead!
We can easily achieve a similar result with much easier to read and idiomatic Python

614 µs ± 8.22 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)After all, there are no explicit append calls!
But wait, there is as always an even more idiomatic and readable version with list comprehensions

454 µs ± 10.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)Beautiful! You can convince yourself that these numbers are real using colab and don’t forget that even though Python’s cost model is very different from languages with optimized compilers, oftentimes slow code is a sign that there is a more performant and idiomatic version waiting to be used.
Even faster:
ls = list(range(N))
187 µs ± 45 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)