The One Property That Makes FlashAttention Possible
What computing an average teaches us about the most important optimization in modern ML

FlashAttention is everywhere.
It’s in PyTorch, JAX, and every LLM serving stack. It delivers 2-4x speedups and cuts memory from O(n²) to O(n).
But ask practitioners why it works, and you get hand-wavy answers about “tiling” and “recomputation.”
Those are implementation details. Today I want to show you the actual why - the mathematical property that makes it all possible.
We’re not starting with attention though. We’re starting with something simpler: computing an average.
A Simple Problem: The Average
You have a billion numbers. You want their average.
The obvious approach:
One number at a time. One core. One long wait.
But here’s the thing: you don’t have to process them in order.
Split the data into chunks. Compute each chunk’s sum and count separately:
Then combine:
Same answer. But now you can process chunks in parallel.
Why This Works: Associativity
This works because addition is associative:
Grouping doesn’t change the result.
More precisely: the pair (sum, count) can be combined, and that combination is associative. This single property unlocks three capabilities:
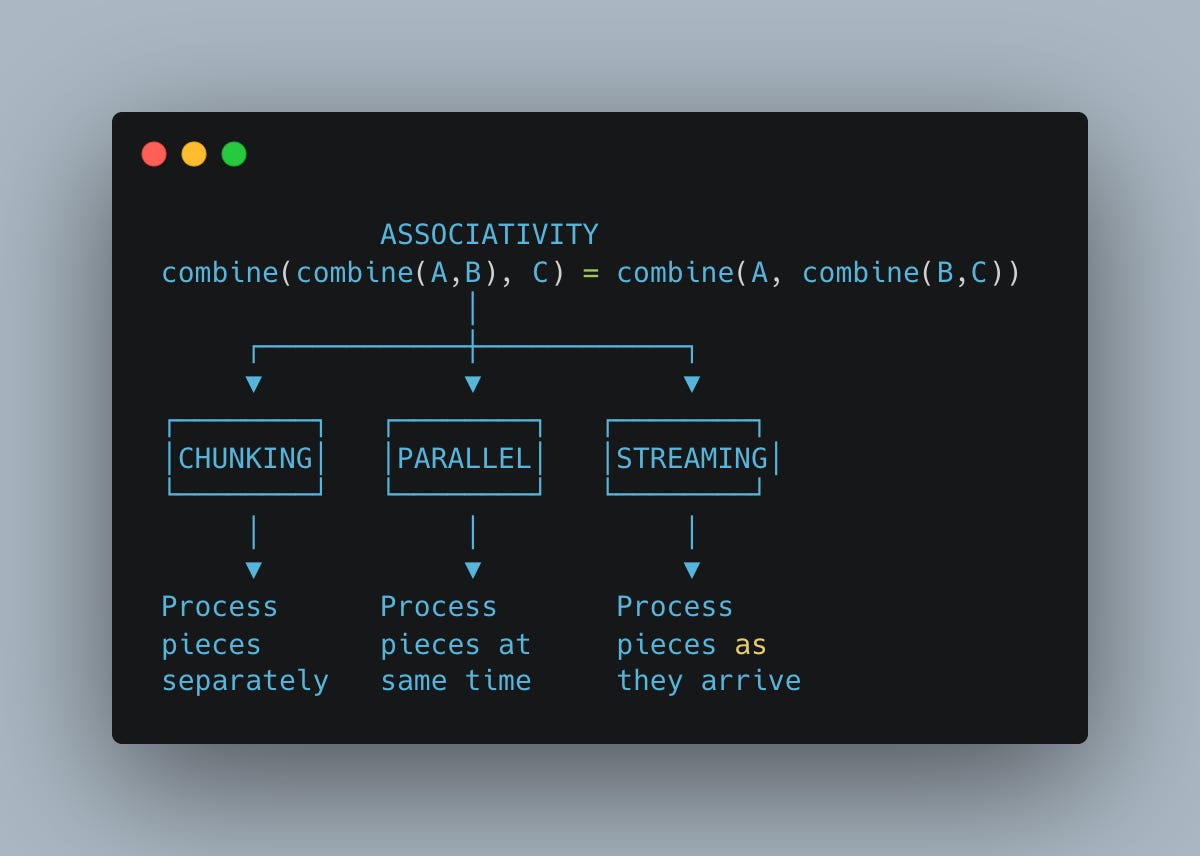
One algebraic property, three capabilities. If your combination operation is associative, you can split, parallelize, and stream - automatically.
This might seem obvious for averages. But the same principle - find combinable state, verify associativity - applies to surprisingly complex operations.
Let’s try something harder.
Why Softmax Seems Different
Softmax is the heart of attention:
To compute any output, you need the sum over all elements.
If I show you half the values, you can’t produce final outputs. You’re missing half the denominator. Unlike our average, where partial sums combine cleanly, softmax seems to require everything upfront.
Can we find hidden associative structure anyway?
Before we answer, we need to address a practical problem.
The Overflow Problem
Here’s what breaks naive softmax:
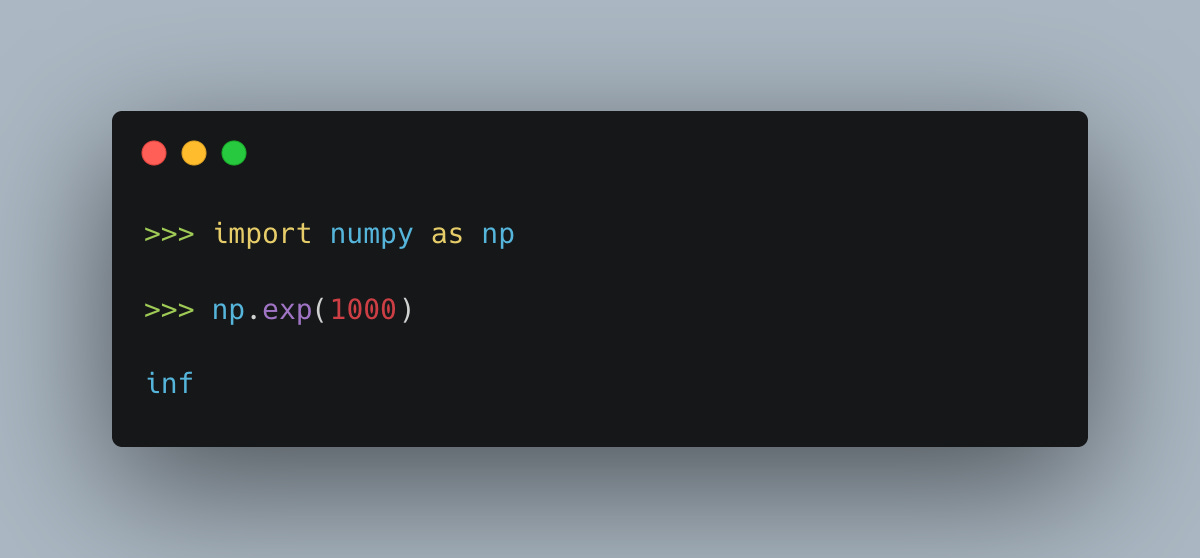
When values are large, exp() overflows to infinity. And attention scores can be large.
The fix exploits a mathematical identity—softmax is translation-invariant:
for any constant c.
Subtracting the same value from every element doesn’t change the output. So we subtract the maximum:
Now every exponent is ≤ 0, so exp() never exceeds 1. No overflow.
This is why you see max everywhere in softmax code. It’s not algorithmic - it’s survival.
But now we have two things to track: the max and the sum. Let’s see if they combine.
The State for Softmax
For our average, the state was (sum, count).
For softmax, given values x₁, x₂, ..., xₙ, we need:
- m = max of all values
- s = sum of exp(xᵢ - m)
Can we combine two such pairs from separate chunks?
Why Simple Addition Fails
Say we have:
Chunk A: values [1, 2, 3]
m_a = 3
s_a = exp(1-3) + exp(2-3) + exp(3-3) ≈ 1.50
Chunk B: values [4, 5]
m_b = 5
s_b = exp(4-5) + exp(5-5) ≈ 1.37
The combined max is max(3, 5) = 5.But we can’t just add the sums.
Chunk A’s sum was computed relative to max=3. Chunk B’s sum relative to max=5. They’re in different “units.”
Adding 1.50 + 1.37 = 2.87 would be wrong.
The Correction Factor
Here’s the key insight.
Chunk A computed
.
But relative to the true max of 5, it should be
These relate by:
So we correct chunk A’s sum:
Chunk B needs no correction (its max equals the combined max):
Combined:
Here’s what’s happening visually:
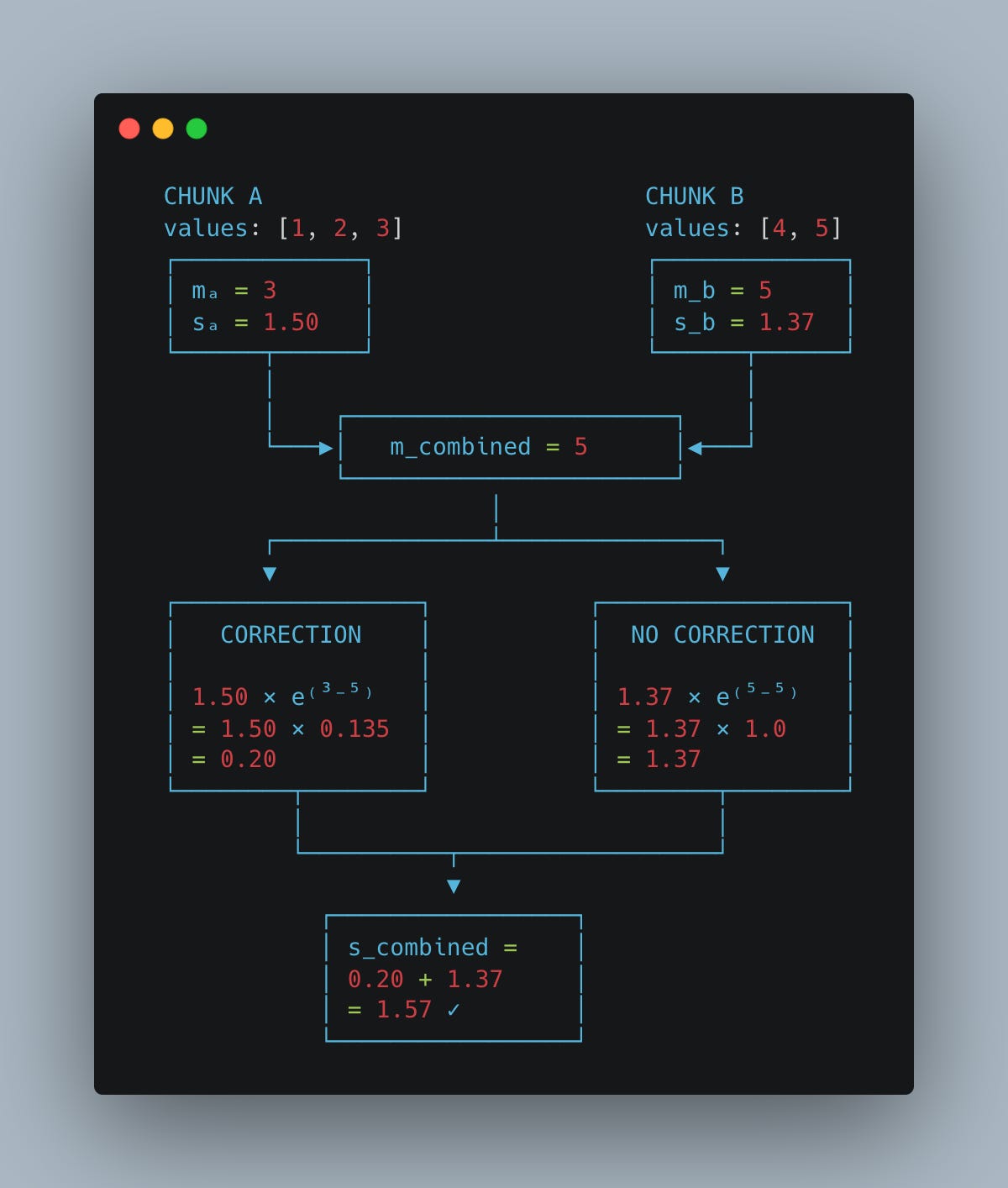
The correction factor exp(m_local - m_global) rescales the local sum to the global reference frame.
Let’s verify by computing directly on [1, 2, 3, 4, 5]:
Same answer. The combination works.
The Combine Rule
We’ve derived the combination for softmax state:
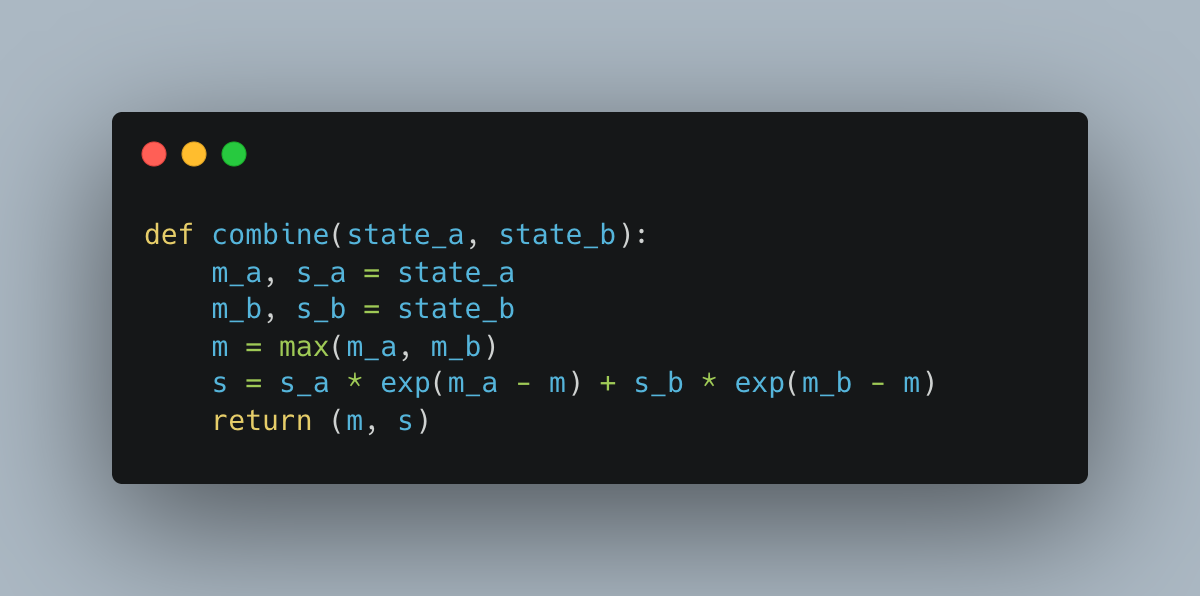
Is this associative?
Yes. The algebra works out:
The pair (max, scaled_sum) forms a monoid—same structure as (sum, count) for averages, just with a more complex combination.
---
The Pattern, Generalized
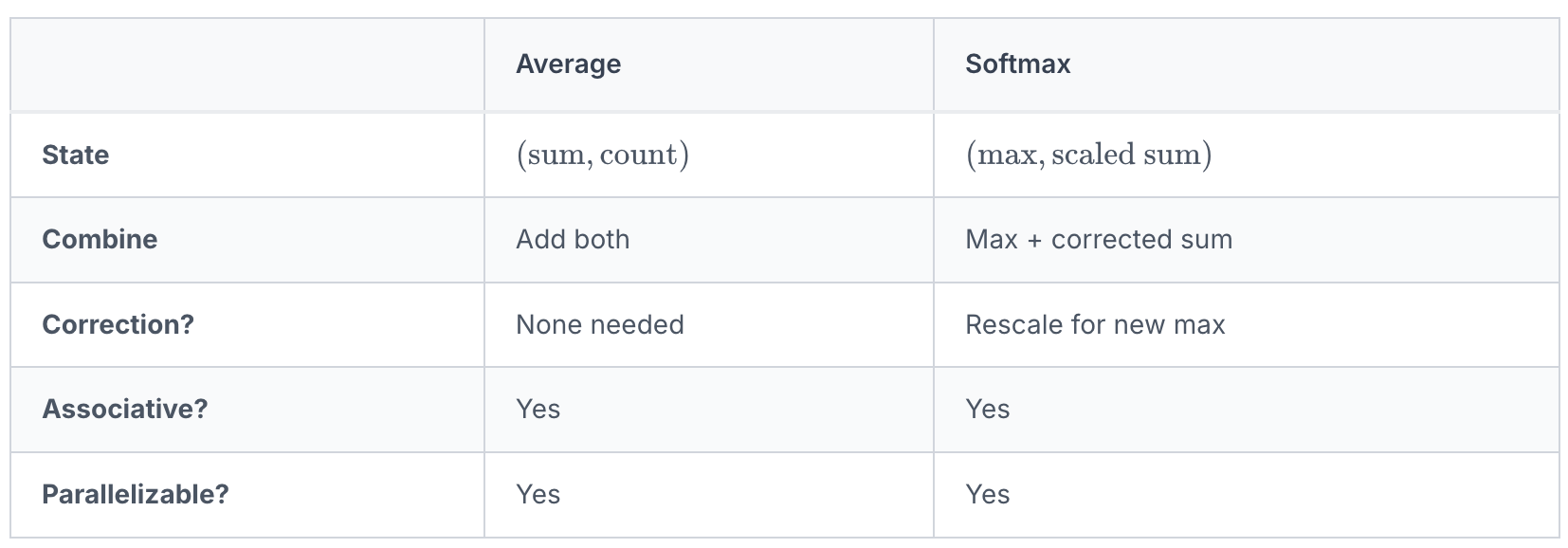
Same structure. Different complexity.
The softmax case requires correction because changing the max changes the meaning of the sum. But the fundamental pattern - combinable state, associative operation - is identical.
FlashAttention: Applying the Pattern
FlashAttention applies this to attention:
Instead of the full n×n matrix, it:
1. Processes tiles of K and V one at a time
2. Maintains running state: (max, sum, output)
3. Applies correction when a new tile reveals a larger max
4. Never materializes the full matrix
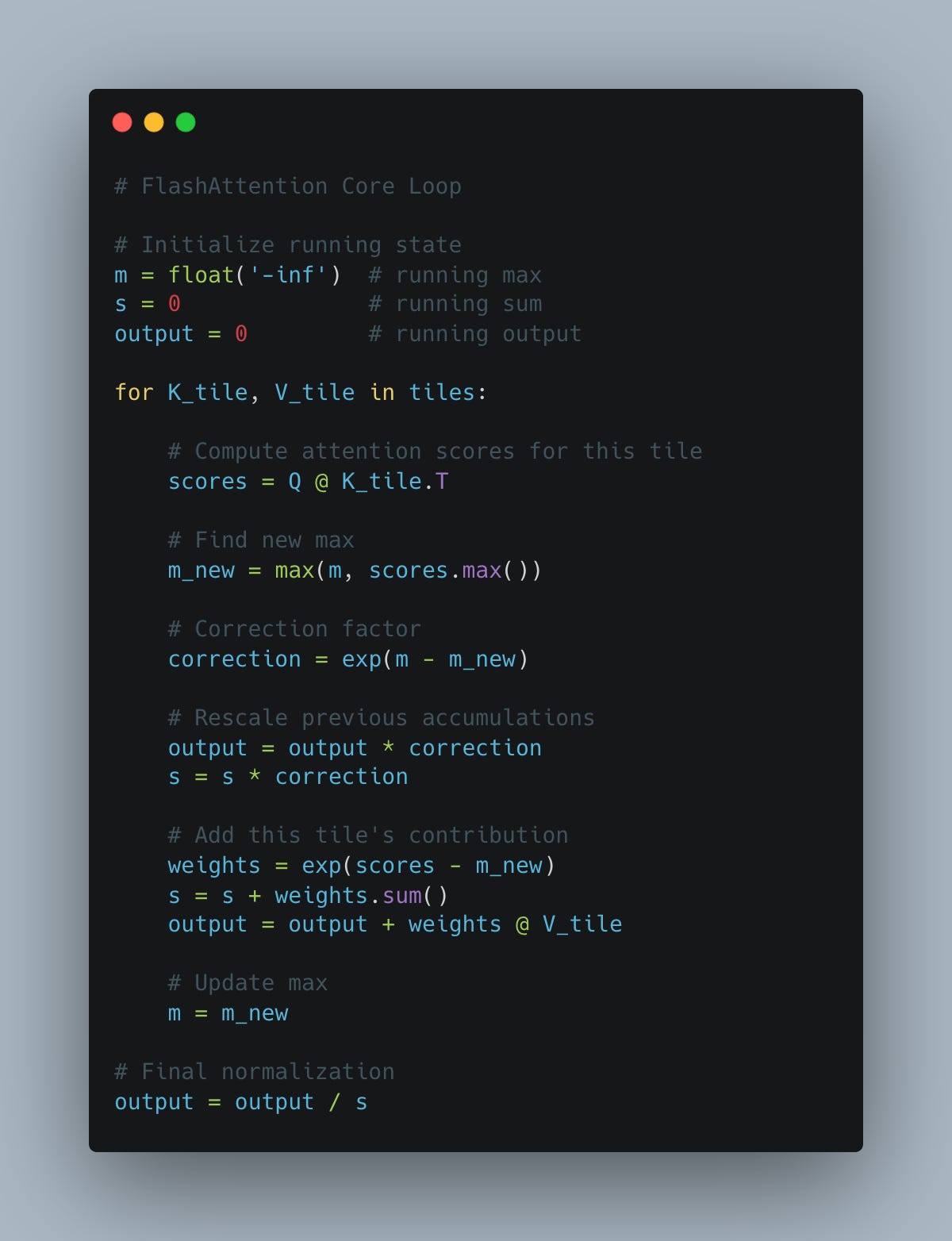
Every tile might reveal a larger max. The correction factor adjusts all previous work. Nothing needs recomputation—the associative structure guarantees consistency.
The Skill to Develop
FlashAttention’s genius isn’t tiling or memory tricks.
It’s recognizing that softmax has **hidden associative structure**.
This is a learnable skill. When facing a “global” computation:
1. What state do I need?
- Average: (sum, count)
- Softmax: (max, sum)
- Your problem: (?, ?)
2. Can partial states combine?
- Write the combine function
- Check: does order matter?
3. Is correction needed?
- Does new information change the meaning of old state?
- If so, what’s the adjustment factor?
4. Is it associative?
- If yes: parallelize, chunk, stream
- If no: fundamentally different algorithm needed
The Counter-Example
Not everything has this structure.
Median:
No way to derive 3.5 from 2 and 5. No combinable state exists.
That’s why median requires sorting or selection—fundamentally different algorithms.
Knowing what can’t be expressed this way is as valuable as knowing what can.
The Takeaway
FlashAttention works because of a mathematical property.
Softmax has associative structure hidden beneath its global-looking surface. The (max, scaled_sum) pair combines across chunks. The combination requires correction, but it’s still associative.
Associativity is the license to parallelize, chunk, and stream.
The property came first. The algorithm followed.
This is the difference between collecting tricks and understanding foundations. Tricks solve one problem. Properties solve a category of problems.
When you face a seemingly global computation, don’t reach for a trick.
Reach for the algebra.
Next week: Why commutativity enables parallelization - and when floating-point arithmetic breaks it.
This series will cover the complete algebraic toolkit for ML performance: commutativity, distributivity, linearity, and the domain transformations that make numerical computing stable.