Tricky optimizer heuristics.
Or when optimization extrapolation fails.

Today we’re tasked with configuring a service. Unfortunately, the API is somewhat dated and is somewhat similar to ioctl - config(int, int). We can write something like

Leaving aside stylistic issues with the code above, e.g. magic constants, this seems somewhat repetitive. Loops to the rescue! Since we are told to always use vectors unless there is a strong reason to use something else we write something like

Again, let’s ignore stylistic issues and get excited about the fact that we no longer have to repeat config invocations. Wait, but don’t we now have a lot of unnecessary runtime overhead? Great question! Compiler explorer readily confirms that clang generates exactly the same assembly as for the manually written version

Perfect! Ship it!
Next day and your manager asks you to add one more config setting. You can now leverage all the boilerplate for the version using vector and simply add one more pair

Simple one-liner. Satisfied with your work, you commit your changes and are done for the day.
But next day instead of gratitude you’re bombarded with angry complaints about increased memory usage and suspicious cost increase. What could have possibly gone wrong?
You start investigation by opening our favorite compiler explorer to see if there is something that is obviously fishy. And you’re in luck as generated assembly looks very different what we’d expect - instead of one more config invocation, there are allocations, deallocations and moves
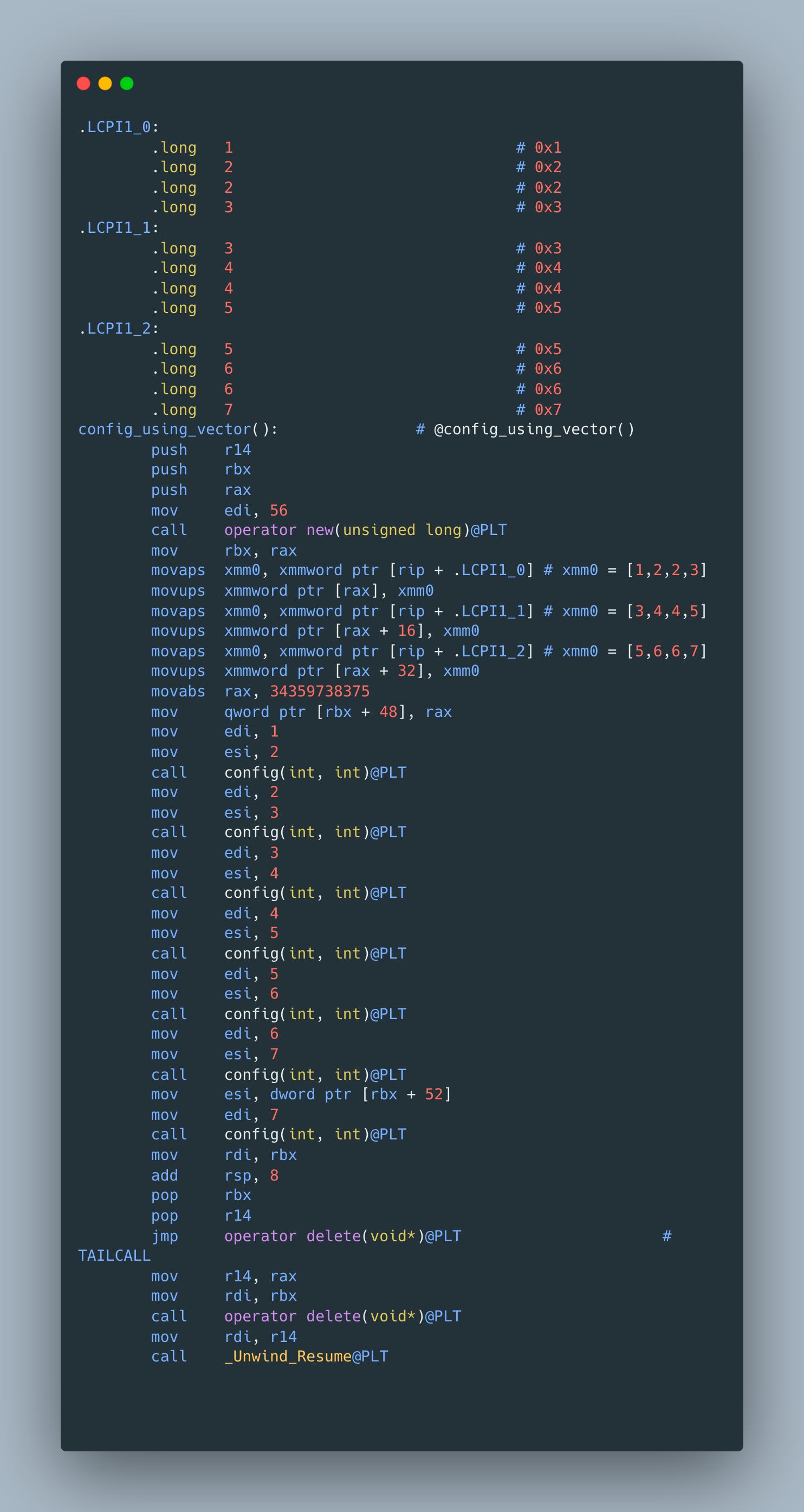
Looks like clang no longer avoids initializer list allocation/destruction and copies our pairs into it. Ouch! Fortunately, from one of the previous articles
we know how to deal with this - just use an array!


So what’s the lesson here? Compilers use a number of heuristics when deciding whether certain optimizations are worthwhile or fit the cost budget - it’s a tricky dance between code size, optimization cost, potential runtime win and other factors. As such, it’s important to verify our assumptions on the code that is ideally exactly the same as the one we ship to production and not simply extrapolate results from smaller/simpler version to bigger/more complex one. It’s also very useful to verify the results using the same compiler version/flags and do it every time they change. For example, trunk version of GCC produces very different result for array-based implementation

it's funny. Initially I was skimming fast and thought you'll be using an array for the loop. I did not realize that it was a vector. Interesting finds though. There is a limit where the compile/optimizer(?) would say - I'm not doing this nice optimization anymore and falling back to regular allocation.
So in the last snippet, gcc is using jne. Is this worse? in terms of the cpu branch predictor?